【译】Rust 异步编程简介及 Tokio 架构概览
原文:An Introduction to Asynchronous Programming in Rust and a High-level Overview of Tokio's Architecture
链接:https://moslehian.com/posts/2023/1-intro-async-rust-tokio/
日期:2023 年 1 月 25 日

使用异步编程开发的服务可以处理数百万请求,而不会耗尽内存和 CPU 资源。编程语言通常内置了对异步的支持,本文就是对 Rust 语言在这一问题上的探究。Rust 是一种类型安全且内存安全的系统编程语言,它通过编译时规则消除传统语言常见的问题,从而保证程序安全性。后半部分简要介绍 Tokio 的内部运作。Tokio 是 Rust 的异步运行库,提供调度、网络以及用于管理异步任务的许多其他基本操作。运行时库依赖于操作系统来注册和分派异步事件。我们将比较 Linux 提供的不同异步 API,并总结为什么新的 io_uring 接口是最佳方法。本文初稿完成于 2022 年 9 月。
简介
即使不升级硬件也能处理海量请求,当传统多线程程序无法做到这一点的时候,异步编程的需求就诞生了。传统线程拥有自己的调用栈,并且作为上下文切换的一部分,由操作系统周期性地将其放置在 CPU 内核上以推进执行。由于这些内存需求,随着请求数量的增长,为每个请求生成一个线程在内存使用方面变得不可行。在语言层面支持异步编程需要语言本身内置相应的数据结构,以及用于管理异步绿色线程(任务)并在 CPU 内核上调度的运行时库。该运行时库还负责与操作系统交互,并调度与操作系统发出的每个事件相关的资源。
Rust 是一种编程语言,其 1.0 版本发布于 2014 年。这种系统编程语言承诺为所有类型的程序(例如网络服务器、操作系统、GUI 和 CLI 程序、机器学习模型、游戏引擎等)提供安全性和效率。Rust 在编译时会强制执行一些规则,来保证程序员编写内存和类型安全的代码,而无需过多的测试。即使有测试,传统编程语言(例如 C/C++)仍然无法创建内存安全的程序,即使这些程序由世界上最优秀的程序员编写。导致软件存在危险漏洞的一些内存问题包括缓冲区和栈溢出、释放后使用、越界索引、重复释放等。Rust 尝试在编译时解决所有这些问题,同时为程序员提供现代且标准的语法。
Rust 语言内置异步支持。Rust 使用 Futures(可能在将来可用的值)和状态机概念来创建可恢复的绿色线程,这些线程使用协作策略来运行自己直到完成。一个 Future 内部可以包含其他 Futures,从而创建一个树状结构,其中根部的 Future(称为任务 task)由运行时直接管理,当运行时轮询 task 以使其执行时,task 会轮询其内部 Futures 直到完成。此树的叶 Futures 与 I/O 驱动程序和操作系统通信,它们向操作系统注册资源并等待操作系统发出事件,保存这些资源的状态。
Tokio 是 Rust 的异步运行时库。它提供调度器、I/O 和时间驱动程序以及其他功能,例如网络、任务间通信和同步原语。Tokio 提供了一个多线程调度器,可以在不同的线程上创建多个工作线程。每个工作线程都拥有一个运行队列,用于存放任务;然后它们从运行队列中弹出任务并驱使其完成。I/O 驱动程序对不同操作系统注册事件的方式做了一层抽象。然后,它等待来自操作系统的事件,并遍历所有事件,调度那些被每个事件关联的资源阻塞的任务。
Linux 提供为异步操作提供了不同的系统调用,这些系统调用会告诉被调用方其对应文件描述符的就绪情况。这些系统调用的问题在于,它们对于文件操作并不按预期工作,并且总是为由常规文件支持的文件描述符返回读取状态。出于这个原因,io_uring 在 2019 年被引入到 Linux 内核中。它提供统一的异步接口,程序可以用来管理所有异步操作。
Rust 编程语言
Rust 是一种新编程语言,旨在按照现代标准创建安全高效的系统。Rust 的安全性源于一套会在编译时强制执行的规则。这些规则的目的是捕获内存错误和多线程程序中的竞争条件。Rust 在做到这些的同时,仍然能保持与 C 语言一样高效。软件漏洞很大一部分原因是内存安全漏洞,例如缓冲区溢出、释放后使用和数组越界访问等。通过静态检查 C/C++ 代码来减少这些内存漏洞的尝试有很多,但大多徒劳无功。如今,超过 70% 的软件漏洞都是由内存安全问题引起的1。因此,像谷歌和 Mozilla 这样的公司分别推出了 Go 和 Rust 语言。这些新语言旨在像 C/C++ 一样高效,但没有它们的内存问题。Rust 与 Go 在内存管理方式上有所不同; Go 采用垃圾回收机制,而 Rust 没有垃圾回收机制,大多数值会在作用域结束时自动释放。
自 2016 年以来,Rust 每年都被 Stackoverflow 评选为最受喜爱的语言2 ,并且在公司和个人开发者中得到了广泛采用。例如,在嵌入式领域,意法半导体(STMicrocontrollers)和 Espressif Systems 等公司推出了社区项目,支持在其 SoC 和模块上使用 Rust 编程语言。
Rust 编程语言最早于 2009 年在 Mozilla 诞生,并在 2014 年迎来了 1.0 版本。Rust 通过两个新概念来实现其安全性:所有权和生存期,我们稍后会详细讨论。使用 Rust 的主要缺点是其陡峭的学习曲线。与 Haskell 或 Prolog 等语言一样,Rust 引入了新概念和新语义,与大多数系统程序员习惯的语言有很大差异。刚开始学习 Rust 的时候,大部分时间都会花在与编译器较劲,让代码运行起来。
概述
Rust 师从面向对象和函数式编程范式。它支持泛型、枚举、模式匹配和模块,并可以使用 trait 来支持多态;trait 类似于 Java 中的接口,允许实现它们的类型被用作该 trait 的实例或对其他类型进行约束。变量默认是不可变的,只有使用 mut 关键字明确标记后才能修改。
Rust 最受欢迎的功能之一是其易于使用的构建系统和包管理器 Cargo。Cargo 可以下载包、解析依赖项、为不同目标构建项目等等。Rust 拥有一个拥有超过 50,000 个包(在 Rust 中称为 crate)的包注册表。
所有权
因为不使用垃圾回收,Rust 需要知道何时释放值;它使用所有权的概念来实现这一点。所有权有三个由编译器强制执行的规则:
- Rust 中的值只有一个所有者。
- 一个值在同一时间只能有一个所有者。
- 当所有者超出作用域时,该值将被释放。在 列表 1 中我们可以看到一个例子。在第 11 行使用花括号启动了一个新的作用域;这个作用域在第 15 行结束。在第 12 行创建了一个名为 $x$ 的新变量并赋值为 22。在它的作用域于第 15 行结束后,$x$ 被释放了。如果我们尝试在第 17 行使用 $x$ 的值,就会遇到编译错误。
fn total(numbers Vec<i32>) -> i32 {
let mut sum = 0; // create a mutable variable
for num in numbers {
sum = sum + num
}
sum
}
fn main() {
{
let x = 22;
println!("x: {}", x);
}
// println!("x: {}", x); //! compile error
let a = vec![1, 2, 3]; // a heap allocated array
let b = a; // move ownership of array from 'a' to 'b'
println!("b: {:?}", b); // This is correct
// println!("a: {:?}", a); //! compile error
let t = total(b); // b is moved
// println!("numbers {}", b); //! compile error
}第 19 行在堆上创建了一个数组(向量)并将其赋值给不可变的变量 $a$。 然后向量的所有权从 $a$ 转移到另一个名为 $b$ 的变量。 完成此赋值后,我们将无法再使用 $a$,并且第 23 行的打印语句会因编译时错误而失败。
$b$ 接着作为参数传递给只接受一个向量作为参数的函数。 在这种情况下,我们向量的所有权会传递到函数中,并赋值给函数内的变量 $numbers$。当函数执行完毕后,向量将被释放,因为拥有它的变量 $numbers$ 出作用域了。因此,在第 27 行尝试使用 $b$ 也会导致编译错误。3(第~4.1章)
借用
如果您想使用一个变量但是不获取它的所有权,Rust 提供了一个称为「借用」的概念。借用在某种意义上是经过静态检查的引用或指针,只要满足以下条件之一,就可以使用没有所有权的变量:
- 只能存在一个可变借用指向某个变量
- 可以存在任意数量的不可变借用指向某个变量
在 列表 2 中,创建了一个向量并将其分配给名为 $nums$ 的变量。第 4 行和第 5 行分别创建了两个不可变借用。第 6 行尝试将新值压入 $nums$ 失败,因为使用关联函数(例如 push)需要该变量的可变借用,这违反了借用条件:一个变量既不能同时拥有可变借用又拥有其他不可变借用。第 7 行的语句也因相同的原因而失败。第 11 行,当这些借用超出作用域后,就可以对变量进行可变借用了。
fn main() {
let mut nums = vec![1, 2, 3];
{
let nums1 = &nums; // first reference
let nums2 = &nums; // second reference
// nums.push(4); // ! compile error
// let mut nums3 = &mut nums; // ! compile error
// nums3.push(4); // ! compile error
println!("ref1: {:?}, ref2: {:?}", nums1, nums2);
}
nums.push(5);
let mut nums4 = &mut nums;
nums4.push(6);
// nums.push(7); ! compile error
println!("{:?}", nums4);
}第 13 行创建了一个新的可变借用。由于同一时间只能存在一个可变借用指向某个变量(与之前提到的 push 函数需要获取关联变量的可变借用相同)。需要注意的是,如果删除第 17 行的语句,那么第 15 行的 push 操作就不会失败。这是因为 Rust 编译器足够智能,能够识别到可变借用 $num4$ 在 push 操作之后就不再被使用了,并且会在 push 之后立即释放。
这些规则由 Rust 编译器强制执行,可以防止之前描述过的内存安全问题,例如多次释放、释放后使用和数据竞争。然而,这些规则也让程序员难以轻松创建诸如链表之类的数据结构或与硬件交互,并迫使他们使用 unsafe 代码块。在这些代码块中,Rust 的所有权和借用规则不适用。3(第 4.2 章)
生命周期
Rust 通过使用生命周期避免在其他地方释放资源后仍在使用它的情况。生命周期和生命周期注解允许编译器理解变量的有效范围。在大多数情况下,Rust 编译器可以推断变量的生命周期,无需手动标注。例如,列表 2 中的 nums2 和 nums1 的生命周期在第 10 行结束。
需要手动添加生命周期注解的示例在列表 3 中进行描述。在这个例子中,smaller 函数接受两个引用并返回一个引用。如果不使用生命周期注解,我们无法让编译器确保程序运行时避免函数返回的引用已经提前被释放,从而变成无效引用。生命周期注解就像类型一样;有时你需要手动指定变量的类型,因为编译器无法推断它。在我们的例子中,生命周期注解定义了程序员期望的输入和输出之间的关系,然后编译器可以对其进行分析 3(第 10.3 章)。
生命周期注解 ‘a 告诉编译器,返回值的生存期应与两个输入引用的较小生存期一样长。
fn smaller<'a>(str1: &'a str, str2: &'a str) -> &'a str {
if str1.bytes().len() < str2.bytes().len() {
str1
} else {
str2
}
}
fn main() {
let name1 = String::from("Arash");
let name2 = String::from("Kiarash");
println!("{}", smaller(&name1, &name2));
}并发
Rust 没有提供用于管理和调度线程的运行时库,而是使用一对一映射模型,其所有线程都映射到操作系统线程。Rust 支持同步原语,例如互斥锁 (mutex)、条件变量、原子操作、栅栏(barriers)等。Rust 使用生命周期来决定何时解锁资源;如果锁保护的资源超出作用域,则会解锁该锁。可以在线程之间通过消息传递机制(例如管道 (channel))发送变量的所有权。需要注意的是,Rust 无法阻止程序员使用原始同步原语创建死锁 3(第 16.1 章)。
小结
在本节中,我们介绍了 Rust,这是一种相对年轻的系统编程语言,它提供了与 C/C++ 等其他语言相比更高的效率和安全性保证。我们概述了导致其在 Mozilla 创建的原因,并讨论了 Rust 编译器消除困扰传统编程语言的内存安全和类型安全问题的机制和规则。
异步编程
本章将讨论多任务(multitasking),即操作系统能够同时运行多个任务的功能。我们将探讨抢占式和协作式多任务,并简要介绍 Rust 如何实现异步性。
多任务
在主流服务器或个人计算机中(嵌入式设备除外),能够同时执行多个任务是必不可少的。例如,在物理服务器或虚拟机上,可以同时运行多个进程:一个用于邮件服务器,一个用于提供网页服务,另一个通过 vpn 路由流量等等。
在大多数情况下,任务数量要多于 CPU 核心数量,因此操作系统要想同时运行所有这些任务,就需要在单个核心上调度多个任务。为了让人感觉所有这些任务都同时运行,操作系统会定期将正在运行的任务替换为在时间片上轮到自己的任务。这就是并发,一种所有任务同时运行的错觉。并行是指任务在不同的内核上真正同时执行。
实现多任务有两种主要方式:
- 操作系统强制暂停任务的执行,并将其与另一个等待中的任务进行切换。
- 任务本身放弃对 CPU 的控制权 (yield),以便其他任务可以执行。
抢占式调度和多线程
在抢占式调度中,操作系统可以根据硬件中断来决定何时切换任务。此中断可能是硬件计时器超时或其他中断源的结果。在图 1 中我们可以看到,当 CPU 正在执行任务 A 时,发生硬件中断,操作系统接管 CPU 以执行相应的中断处理程序,并将任务 A 与任务 B 切换 4。

在大多数操作系统中,这些任务称为执行线程,每个线程都拥有操作系统单独保留的调用栈。为了稍后恢复线程,CPU 需要在抢占发生时保存线程的状态。这需要保存抢占点的所有 CPU 寄存器,并在线程恢复时还原它们。这些线程由操作系统复用,并且准备好执行的线程会获得 CPU 周期。如果线程因某些操作而阻塞,或者其时间片结束,操作系统就会将该线程换成另一个就绪的线程。
对于许多应用程序来说,使用线程从套接字读取数据或写入文件是合适的。它们的优点是它们的执行由操作系统控制,CPU 时间在它们之间公平分配。另外,在任务可能由不可信的应用程序生成的环境中,操作系统能够暂停它们的执行非常重要。它们的问题在于每个线程都需要自己的调用栈,因此生成的线程越多,内存使用量就越高。在线程之间切换时,保存寄存器并在线程继续执行时再次还原寄存器会产生开销。当应用程序需要高性能时,这种操作系统级别的线程来回切换代价很高。
如果您使用阻塞接口进行 I/O 操作,例如等待从该套接字读取 x 个字节,那么您将需要为每个调用单独分配一个线程;一个线程从套接字读取,另一个线程从数据库中获取一些记录,等等。
这种方法中,应用程序使用操作系统 API 创建用户线程,这些用户线程映射到内核线程。这样,应用程序就不需要具备管理线程的功能,并且可执行文件大小也更小。
协作式调度和异步
在协作式调度中,任务本身会放弃执行以允许其他任务在 CPU 上运行。这不同于抢占式调度,在抢占式调度中,操作系统会强制暂停任务的执行 4。协作通常借助编程语言、编译器和运行时库来完成。此运行时库可以嵌入到语言本身中,也可以像 Rust 一样作为依赖项包含进来。
协作式调度适用于大量 I/O 操作的场景,如果为每个阻塞操作使用线程,那么该线程的大部分时间都将简单地用于等待该操作完成(等待来自套接字的字节到达或从磁盘读取文件)。然而,在异步操作中,调用线程不会傻等操作可用,而是简单地去做其他事情。当与异步操作相关的资源准备就绪时,它会通知线程可以开始执行该异步操作之后的代码。
在这种类型的调度中,任务比线程更细粒度,可以将多个任务分配到单个线程上运行。例如,我们可以创建一个用于监听套接字的任务 TaskA 和另一个用于将一些信息保存到数据库的任务 TaskB。这两个任务都可以运行在同一个线程上。当 TaskA 尝试从套接字读取数据但没有可用数据时,它会保存其状态并让出执行权。之后,由于我们的线程现在无所事事,它可以尝试执行 TaskB;TaskB 执行并尝试尽可能多地写入字节,然后保存其状态并让出执行权给运行时库。现在我们的线程进入睡眠状态,等待任何一个任务可供执行。例如,如果套接字上有新的字节可用,操作系统会通知运行时库,运行时库会唤醒 TaskA 并将其置于我们的线程上执行。图 2 展示了这样一个场景的例子。
保存状态通常由编程语言完成。在 Rust 中,任务所需的所有状态,例如局部变量或调用栈的一部分,都存储在一个结构体 (struct) 中。用于创建此结构体并将值插入其中的代码由编译器自动生成。通过这种方式,任务不需要单独的调用栈,而是使用共享的调用栈(即它们运行所在的线程的调用栈)。现在我们可以生成数百万个任务,而不必担心内存限制。
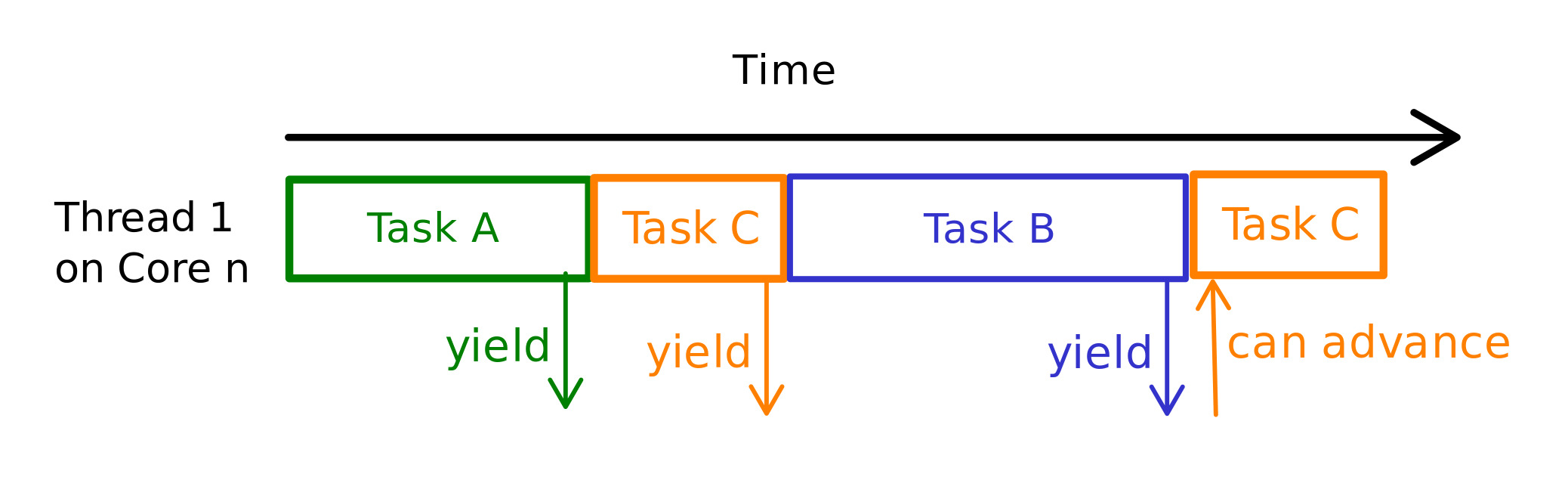
这是一种多对一映射的方式,其中多个用户任务映射到用户线程,用户线程本身又映射到内核线程。它的缺点是,一个不放弃执行权的异常任务 (rouge task) 可以饿死所有其他等待执行的任务。因此,协作式调度通常用于任务可信赖的环境中,例如项目内部,任务由开发人员自己创建。
对比
让我们看一个例子,概述多线程和异步的区别。在 列表 4 中,我们可以看到一个简单的 TCP 服务器,它监听端口等待新连接。每次客户端建立连接时,它都会为客户端创建一个新的套接字,并将该连接传递给一个新线程。handle_connection 函数用于在单独的线程上管理单个连接。
取决于运行此服务器的机器的内存,这种方法可能适用于数千个连接;但是当连接数量达到数百万时,服务器进程的内存需求不可能得到满足。
fn main() {
let listener = TcpListener::bind("127.0.0.1:8090").unwrap();
for socket_wrapped in listener.incoming() {
let socket = socket_wrapped.unwrap();
thread::spawn(|| {
handle_connection(socket);
});
}
}我们可以用 Rust 中的异步任务来并发处理连接。通过这种方式,单个线程可以处理多个任务,最大连接数可以提升至数百万级(当然,如果忽略其他限制的话)。列表 5 中的代码展示了使用 Tokio 运行时在 Rust 中使用异步任务的示例。正如你所看到的,异步代码看起来非常像普通的同步代码。
#[tokio::main]
async fn main() {
let listener = TcpListener::bind("127.0.0.1:8090").await.unwrap();
loop {
let (mut socket, _) = listener.accept().await.unwrap();
tokio::spawn(async move {
handle_connection(socket);
});
}
}Futures and 状态机(State Machine)
Rust 使用 futures 和 async/await 支持协作任务。future 是一个稍后可用的值。调用者不必阻塞等待值可用,而是可以继续做其他事情,只有在 future 完成并且值准备就绪时才切换回来。Rust 中的协作任务是一种 future,future 是实现名为 Future trait (接口) 的结构体(列表 6)。实现 Future trait 的类型要求实现一个名为 poll 的方法,并指示 future 最终返回的值。它还可以指定最终的值的类型。例如,你可以调用一个返回当前进程打开的文件描述符数量的 future;当这个 future 完成时,它会返回一个整数类型的值。
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context)
-> Poll<Self::Output>;
}
pub enum Poll<T> {
Ready(T),
Pending,
}poll 方法的返回值类型是一个叫做 Poll 的枚举,它包含两个变体。调用 poll 方法会尝试运行该 future 直到完成;如果 future 完成了,它会返回 Ready(T),其中 T 是值的数据类型。如果 future 还未完成,则会返回 Pending。
async 和 await
Rust 的异步函数会返回一个实现了 Future trait 的结构体,该结构体拥有 poll 方法。如果这个 future 完成了,Ready(T) 中的 T 类型就和 async 函数的返回值类型相同。这由编译器自动完成,可以让程序员编写的异步代码看起来更接近同步代码。我们可以在 async 函数内部使用 await 关键字来等待另一个 future 的值。
Rust 编译器会将 async 函数转换为一个状态机(一种结构体),该状态机实现了 Future trait。这个状态机就是调用 async 函数时返回的 future。列表 7 是这类函数的示例。在第 4 行,我们使用 await 等待将整个文件的内容读入字节数组;当执行任务到达这条语句时,由于从磁盘读取数据比处理器的速度慢得多,任务会立即返回 Poll::Pending 以允许其他任务继续执行。read_all_file 是另一个 async 函数,调用它会返回一个 future;await 这个 future 会导致外部的 future(我们的 async 函数)停止继续执行,并导致外部函数返回 5 6 7。
当文件被读入到 file_bytes 缓冲区后,pipe_to_socket future 会再次被轮询,它会从中断处恢复,然后在第 6 行 await 另一个尝试创建 UDP 套接字的 future。这样一直持续到整个函数执行完成;每次函数遇到 await 点时,它都会让出控制权给运行时系统,以便其他任务可以继续执行。函数的状态会在每个 await 点保存下来。例如,当等待从套接字接收字节时,file_bytes 和 socket 变量会保存在编译器生成的结构体中,并在 future(我们的函数)再次被轮询以恢复时使用。
async fn pipe_to_socket() -> i32 {
// Read all the contents of a file
let file_bytes = read_all_file("myFile.txt").await;
// Create a UDP socket
let socket = UdpSocket::bind("0.0.0.0:8080").await;
// Receive some data from a client
let (len, addr) = socket.recv_from(&mut [0; 1024]).await;
// Send all the contents of the file
write_all_socket(socket, addr, file_bytes).await;
return len;
}主动让出执行权并稍后恢复执行会创建一个状态机。图 3 展示了 列表 7 async 函数的状态机。
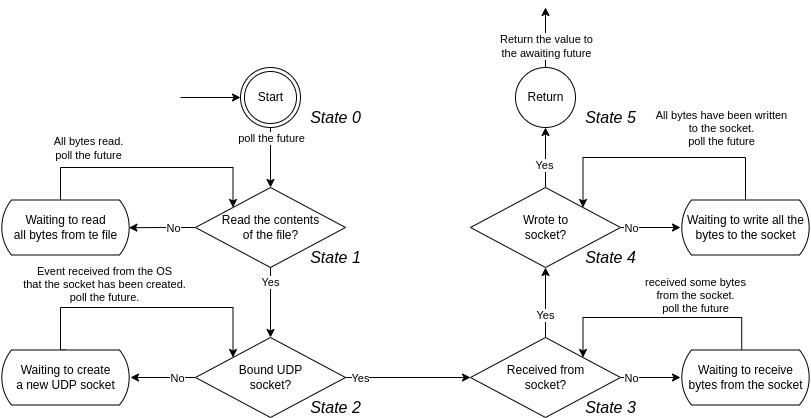
正如你所看到的,每当执行一个 future 时遇到 await 点,控制权就会让回给运行时去执行其他任务。当 future 等待的事件发生后,运行时会找到等待该事件的 future 并再次尝试轮询它,以便 future 可以继续执行。每次 future 遇到资源等待点时,运行时都会将该资源注册到例如操作系统上。然后,运行时会监听事件。这些事件来自操作系统,表明运行时注册的某些资源现在已经准备就绪 7。
编译器生成的状态机可能是什么样子,可以见 列表 8 中的示例(请注意,代码在语义上可能不正确,但仍然可以很好地举例说明 futures 的内部行为)。我们的状态机的类型可以是一个简单的枚举,包含 6 个不同的变体。每个变体都是一个状态,其中包含了暂停和恢复状态机所需的所有必要数据。我们为这个类型实现了 Future trait 并添加了一个 poll 方法。每次调用 poll 方法时,它都会尝试推进状态机。它首先使用模式匹配确定当前所处状态,然后运行为该状态生成的代码。
例如,如果状态机处于 State1 并且被运行时轮询,它首先会提取存储在当前状态中的变量,对于 State1 来说,唯一的变量就是另一个 future。这个 future 是从 State0 转换到 State1 时调用 async 函数 read_all_file 的结果。然后它会尝试轮询 read_all_file future,如果 future 还没有准备好并返回 Pending,那么我们外部 future 的结果也会是 Pending。然而,如果轮询 read_all_file 返回 Poll::Ready(file_bytes),那么我们可以通过首先创建一个 State2 的实例并传入所需变量(命名我们的字节数组和调用 UdpSocket::bind 的结果,它也是一个 future)来转换到下一个状态 State2。这些变量是我们状态机携带的状态的一部分。
enum PipeToSocketStateMachine {
Start(),
State1 { read_all_file: impl Future<Output = Vec<u8>> },
State2 { file_bytes: Vec<u8>,
bind: impl Future<Output = UdpSocket> },
State3 { file_bytes: Vec<u8>,
socket: UdpSocket,
recv_from: impl Future<Output = (usize, SocketAddr)> },
State4 { file_bytes: Vec<u8>,
socket: UdpSocket,
len: usize,
addr: SocketAddr,
write_all_socket: impl Future<Output = ()> },
Return(),
}
impl Future for PipeToSocketStateMachine {
type Output = i32;
fn poll(self: Pin<&mut Self>,
cx: &mut Context) -> Poll<Self::Output> {
loop {
match self {
PipeToSocketStateMachine::
Start() => {…}
PipeToSocketStateMachine::
State1{read_all_file} => {
match read_all_file.poll(cx) {
Poll::Ready(file_bytes) => {
// Proceed to the next state
*self = PipeToSocketStateMachine::State2 {
file_bytes,
bind: UdpSocket::bind("0.0.0.0:8080")
}
},
Poll::Pending => {
return Poll::Pending
}
}
}
PipeToSocketStateMachine::
State2{file_bytes, bind} => {…}
PipeToSocketStateMachine::
State3{file_bytes, socket, recv_from}
=> {…}
PipeToSocketStateMachine::
State4{file_bytes, socket, len,
addr, write_all_socket} => {…}
PipeToSocketStateMachine::
Return(state) => {…}
}
}
}
}这个状态机由生成器(generators)生成。生成器是一个“可恢复函数”,在语法上类似于闭包,但是在编译器本身编译时会生成完全不同的语义 8。Rust 编译器会在 await 的位置插入 yield 操作,这样当 await 的结果为 Pending 时,future 就会暂停并让出控制权;因此,每次 yield 实际上都是我们状态机的一个状态。列表 6 中的 Pin 类型确保包装类型不会在内存中移动; 这对于自引用结构体来说很重要,因为如果对象被移动,它内部指向自己的指针将会失效。编译器生成的状态机拥有这些自引用指针,因此这些 future 必须被 pinned 7.
执行器 (Executors)
当一个 future 被轮询 (poll) 并且返回 Pending 时,需要有东西在它可以继续执行的时候再次轮询它,否则我们的状态机将不会推进。在前几节中,我们提到“运行时 (runtime)”会进行轮询,这没说错;运行时中负责将 future 轮询至完成的部分称为执行器 (executor)。示例 9 展示了一个非常基本和原始的执行器。它有一个队列,可以将 future 作为任务推入其中,并且会反复尝试从队列头部弹出任务并运行它。任务是执行器处理的 future;示例 10 中概述了一个任务的例子。任务通常是包含 future 实例的结构体,当我们说“运行任务”时,指的是轮询任务内部的 future 6.
while let Some(task) = self.queue.pop() {
task.run();
}pub struct Task {
...
future: Pin<Box<dyn Future<Output = ()>>>,
...
}
impl Task {
fn run(&mut self) {
...
match self.future.poll() {
Poll::Pending => {...},
Poll::Ready(val) => {...}
}
...
}
}在示例 9 中,当弹出任务并轮询其 future 时,可能会发生两种情况:任务的 future 返回 Poll::Ready(value),表示任务已完成,无需进一步处理;任务的 future 返回 Poll::Pending,表示该任务需要在稍后再次进行轮询(例如,它可能正在等待套接字操作或从磁盘读取数据)。
为了再次运行任务,需要将其添加回执行器的运行队列中。那么,谁来负责将任务放回队列呢?
唤醒器(Wakers)
Waker 是 Rust 用于向执行器发出信号(轮询内部 future)的机制,指示给定的任务应该再次运行。Waker 拥有一个 wake() 方法,调用该方法会执行此信号操作。在 future 的上下文中,waker 通常会包装在一个 Context 类型中,并传递给 future 的 poll 方法;示例 11 展示了 Context 结构体的例子。对于我们基本的执行器来说,调用任务上下文的 waker 上的 wake() 方法,会简单地将该任务重新添加回执行器的运行队列中,以便再次对其进行轮询。如果执行器处于睡眠状态,也会将其唤醒 6。
pub struct Waker {
...
}
pub struct Context<'a> {
waker: &'a Waker,
}
impl Waker {
pub fn wake(self) {
...
}
}Future 树(Future Tree)
到目前为止,我们看到的所有 future 都可以调用其他 future。例如,在 示例 7 的第 4 行,async pipe_to_socket 函数等待调用 read_all_file 返回的 future 的结果;该函数可能的示例在 示例 12 中展示。函数内部的其他部分也遵循类似的模式。我们等待的 future 本身也可以等待其他 future。这种嵌套的等待关系形成了一个树状结构 9 10.
async fn read_all_file(path: &str) -> Vec<u8> {
let file = File::open(path).await;
let mut buffer = Vec::new();
file.read_to_end(&mut buffer).await;
return buffer;
}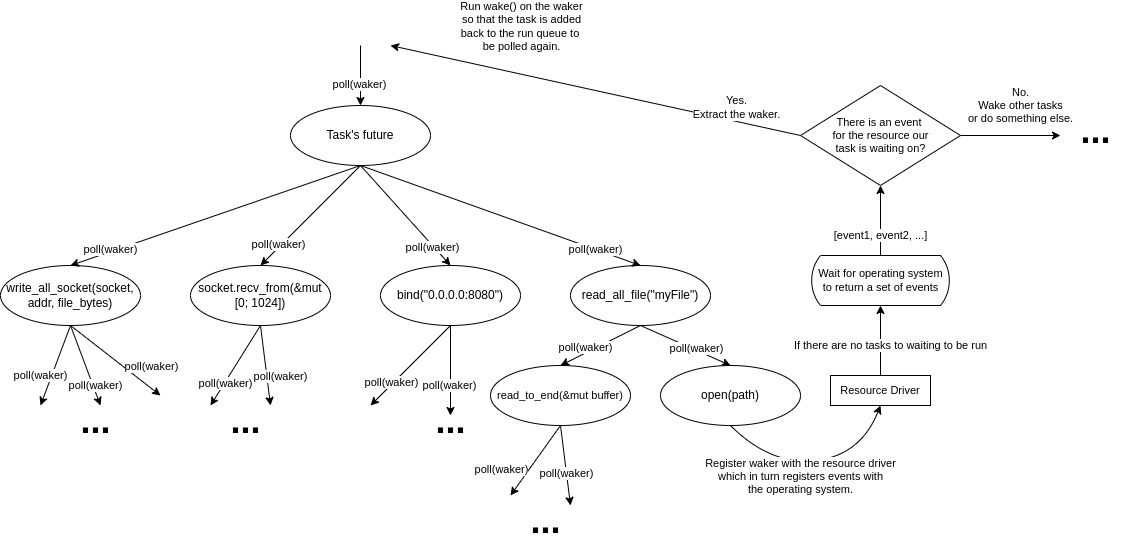
As we can see tasks are the root of our future tree and are the futures that our executor is in contact with. Executors provide APIs for spawning new tasks by giving them a future. In listing 13 we call our async pipe_to_socket function which returns a future, and pass this future to the spawn method of our executor (in this case Tokio’s executor). The spawn method creates a task out of this future and adds it to the run queue of our executor.
正如我们所看到的,任务是 future 树的根节点,也是执行器直接交互的 future。执行器提供了用于生成新任务的 API,只需要提供一个 future 即可。在 示例 13 中,我们调用了 async pipe_to_socket 函数,该函数返回一个 future,然后我们将此 future 传递给执行器的 spawn 方法(在本例中是 Tokio 的执行器)。spawn 方法会将此 future 创建为一个任务,并将其添加到执行器的运行队列中。
#[tokio::main]
async fn main() {
...
tokio::spawn(pipe_to_socket());
...
}正如我们在 示例 8 中第 28 行的状态机看到的,当我们对主任务的 future 调用 poll 时,它会依次尝试轮询其内部的 future。但是我们不能一直轮询其他 future,在树的某个位置,一些 future 在被轮询时除了返回 Poll::Pending 之外,还会确保当它们等待的资源可用时,再次运行轮询它们的 task。这些 future 就是 future 树的叶子节点。在 图 4 中,当我们第一次轮询任务并提供一个 waker 时(该 waker 的 wake() 方法被调用会将任务放回运行队列),它会尝试轮询 read_all_file future。read_all_file future 则会尝试轮询 open(path) future。open(path) future 是一个叶子节点 future,因此当它被轮询时,它不会再轮询其他 future,而是将它的 waker 和它等待的资源注册到驱动程序(也称为反应器 reactor)上。在我们的例子中,future 请求驱动程序使用给定的路径打开一个文件,驱动程序随后会请求操作系统打开给定的文件。注册了驱动程序的 waker 从主任务一直被传递下来,驱动程序会记录哪些 waker 与哪些等待资源相关。然后,叶子 future 返回 Poll::Pending,这个返回值会一直传回任务和执行器。然后,执行器会尝试轮询其他任务。
驱动程序会周期性地等待操作系统返回一组事件。然后,它会遍历这些事件,并调度所有已与此事件资源注册的 waker。在我们的例子中,当文件被操作系统打开后,它会返回一个事件。看到这个事件后,驱动程序会调用与此事件注册的 waker 上的 wake() 方法,并且与此 waker 相关的任务将被推回运行队列再次被轮询。
当任务再次被轮询时,由于我们所有的 future 都可以看作是状态机,并且未来树在某种程度上也是一个状态机树,它将从根 future 一直向下轮询到叶子 future。future 在上次被轮询时会保存其状态,然后则从中断处恢复。这次当叶子 future 被轮询时,它会收到它等待的资源(在我们的例子中,是已打开文件的的文件描述符),并返回 Poll::Ready(fd) 给它的父 future。然后,父 future 会继续轮询下一个 future,依此类推。
小结
在本节中,我们讨论了实现多任务处理的不同方法。我们概述了抢占式调度和协作式调度的优缺点,并讨论了异步如何帮助我们充分利用内存和 CPU 周期。我们看到了 Rust 如何通过使用 async/await 关键字和 future 来实现异步编程。最后,我们看到了一个示例,演示了 Rust 编译器如何帮助我们从这些 future 创建状态机,以及执行器和运行时库如何运行这些 future。
Tokio
Tokio 是 Rust 的异步运行时,它提供了我们在上一节讨论过的用于运行 future 的执行器。它是 Rust 生态系统中迄今为止使用最广泛的运行时,许多其他项目都基于 Tokio 之上。Tokio 提供了大量功能:
- 任务调度器
- 用于与操作系统交互的 I/O 驱动程序(反应器)
- 异步网络接口,例如套接字
- 用于处理异步任务的通信和同步原语,例如各种通道(channels)、互斥体(mutex)、栅栏(barrier)、条件变量(condvar)等
Tokio 被分解成各个模块,每个模块提供不同的功能。这里我们将更深入地研究 runtime 模块。该模块不会向库的用户暴露很多 API;它们中的大多数用于创建运行时或将任务派生到运行时。运行时模块是用 Rust 编写高性能异步代码的点睛之笔,它本身由多个部分组成 11:
- 将任务分配到可用内核上运行的调度器
- 当来自操作系统的的新事件到来时唤醒等待任务的 I/O 驱动程序
- 基于时间调度的时间驱动程序,具有毫秒分辨率
在本章的剩余部分,我们将研究 Tokio 运行时的调度程序和 I/O 驱动程序的内部工作原理。
调度器
调度器的职责是将任务分配到 CPU 内核上,直到任务让出控制权返回给调度器为止。任务内部的 future 会被轮询,它会在 CPU 上运行,直到遇到需要外部资源才能解决的内部 future 为止。Tokio 提供两种调度器:多线程和单线程。这里我们将重点研究多线程调度器(单线程调度器的内部工作原理类似)。
多线程调度器
当使用多线程调度器(默认)时,Tokio 会创建一些线程来调度任务。然后它为每个线程分配一个本地运行队列;然后线程进入一个循环,不断地从队列头弹出任务并运行任务,直到任务让出控制权,然后弹出一个新的任务。当任务被调度到运行时,它们通常会由 I/O 驱动程序批量提交(当从操作系统接收到新事件并且相应的任务被唤醒添加到运行队列时),所有这些任务都会被调度到其中一个线程的本地队列中。如果没有机制将这些负载分配到所有可用线程,我们可能会遇到资源利用不足的情况,即一些线程处于空闲状态,而其他线程则执行了大部分工作。
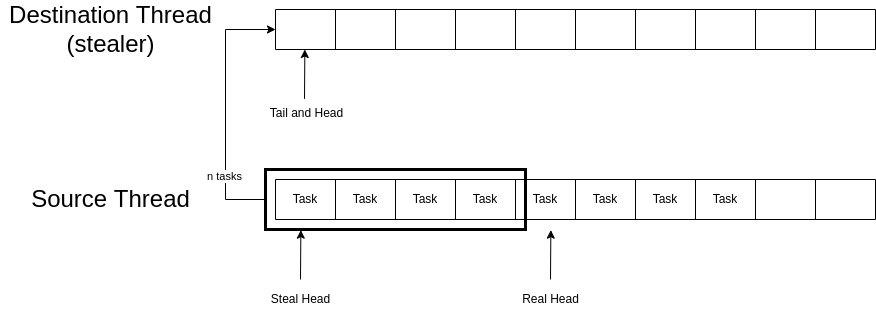
为了解决这个问题并均匀分配工作,Tokio 调度器使用了工作窃取 (work-stealing) 技术。当一个线程无事可做(其本地运行队列为空)时,在进入睡眠状态之前,它会检查其他线程的运行队列是否有工作,并尝试窃取一些任务。如 图 5 所示。线程 2 已经没有任务可运行,在进入睡眠之前,它会检查其他线程是否有工作;它按降序遍历所有线程,并立即发现线程 4 有可以窃取的工作,因此它从线程 4 队列的开头窃取了一半的任务。
这种方法的优点是随着系统负载的增加,可以最大限度地避免同步和跨线程通信,并且线程永远不会到达空队列以尝试从其他线程窃取工作。但是,如果一个线程尝试从其他线程窃取工作,因为没有找到可窃取的工作便进入睡眠状态,然后一批任务被推送到其他线程的运行队列中会怎么样呢?必须实现一种机制,以便具有工作的线程可以通知其他睡眠中的线程,使它们可以唤醒并窃取工作 12.
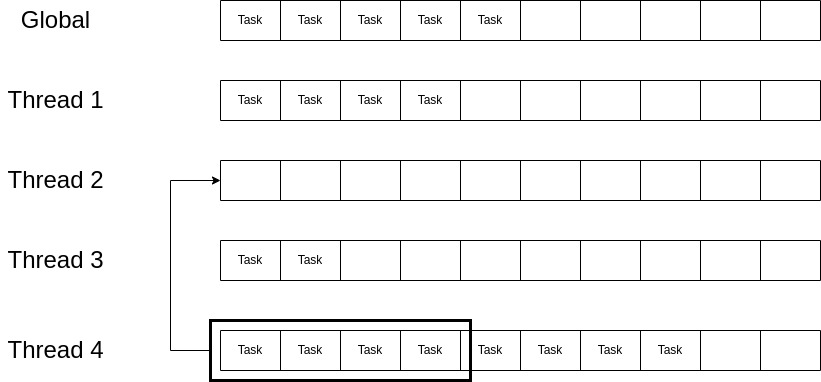
队列和工作窃取的实现
运行队列背后是 列表 14 中概述的循环缓冲区。Arc 类型提供值的共享所有权,并且是一个线程安全的引用计数指针。这意味着它是对堆中对象的引用,可以克隆多次;一旦最后一个引用超出作用域,对象本身就会从堆中删除。循环缓冲区有一个尾部,仅由单个线程更新并由多个线程读取,还有一个头部可以由多个线程并发更新。它由一个固定大小的任务数组支持;该数组的元素一开始没有初始化。Box 类型表示该值将在堆中分配。
每个线程的本地队列都会创建两个句柄,一个是 Steal 句柄,另一个是 Local 句柄。本地句柄由单个线程用于推入和弹出队列中的任务,窃取句柄可供所有其他线程使用,以便它们可以查看此线程的本地队列并在必要时窃取任务。这就是头部和尾部值是原子变量(atomic)的原因;因为它们可能被多个线程写入或读取。
/// Producer handle. May only be used from a single thread.
pub(crate) struct Local {
inner: Arc<Queue>,
}
/// Consumer handle. May be used from many threads.
pub(crate) struct Steal{
inner: Arc<Queue>
};
pub(crate) struct Queue {
/// Concurrently updated by many threads.
head: AtomicU32,
/// Only updated by producer thread but read by many threads.
tail: AtomicU16,
buffer: Box<[MaybeUninit<task::Task>; LOCAL_QUEUE_CAPACITY]>,
}队列的 u32 头部实际上由两个 u16 组成。最左边的 16 位称为窃取头部 (steal head),最右边的 16 位称为真实头部 (real head)。这两个头部用于窃取操作,并向其他线程发出信号,表示当前是否有人正从给定队列中窃取任务。真实头部指向要弹出的下一个任务的位置,窃取头部指向从运行队列窃取的任务的起始位置。
将任务推入队列的方法是首先将任务添加到尾部指示的位置的数组中,然后递增尾部。在推送任务之前,会将真实头部的值减去尾部,并与数组的最大长度进行比较;如果有足够的空间可用,则继续推送。
弹出的操作也很简单,首先检查真实头部和尾部的值是否相等,如果相等,则缓冲区为空,无法弹出任何任务。否则,从缓冲区中取出 real_head 位置的任务,并将 real_head 的值加 1。
impl Steal {
pub(crate) fn steal_into(&self, dst: &mut Local<T>) {
let dst_tail = dst.inner.tail.unsync_load();
let mut prev_packed = self.inner.head.load();
let mut next_packed;
let (src_head_steal, src_head_real) = unpack(prev_packed);
let src_tail = self.inner.tail.load();
// If these two do not match, another thread is concurrently
// stealing from the queue.
if src_head_steal != src_head_real { return 0; }
// Number of available tasks to steal
let n = (src_tail.wrapping_sub(src_head_real)) / 2;
// No tasks available to steal
if n == 0 { return 0; }
// Update the real head index to acquire the tasks.
let steal_to = src_head_real.wrapping_add(n);
next_packed = pack(src_head_steal, steal_to);
// Claim all those tasks.
self.inner.head.compare_exchange(prev_packed, next_packed);
let (first, _) = unpack(next_packed);
for i in 0..n {
// Compute the positions
let src_pos = first.wrapping_add(i);
let dst_pos = dst_tail.wrapping_add(i);
// Read the task
let task = self.inner.buffer[src_pos].read();
// Write the task to the new slot
dst.inner.buffer[dst_pos].write(task);
}
let mut prev_packed = next_packed;
// Update `src_head_steal` to match `src_head_real`
let head = unpack(prev_packed).1;
next_packed = pack(head, head);
self.inner.head.compare_exchange(prev_packed, next_packed);
// No tasks were stolen
if n == 0 { return None; }
// Make the stolen items available to consumers
dst.inner.tail.store(dst_tail.wrapping_add(n));
}
}窃取算法的简化版本概述在 列表 15 中。steal_into 函数由窃取线程在它想要窃取的线程的运行队列的窃取句柄上调用。此函数将本地运行队列句柄作为将被窃取任务的目标队列。窃取线程会将它们自己的运行队列传递给此函数。
第 3 行到第 9 行加载源队列和目标队列的尾部和头部值。头部值分解为窃取头部和真实头部。解包只是简单地将 32 位值拆分为两个 16 位值。在第 13 行,如果源队列的窃取头部和真实头部不匹配,则表示另一个线程正在并发窃取此队列,该函数会立即返回。在第 16 行,要窃取的任务数 n 被分配为源队列上可用任务数量的一半。为了向其他线程发出正在进行窃取操作的信号,源队列的真实头部会在第 22 行提前 n 个位置,然后将头部值重新打包成一个 32 位数字后,放回源队列的原子头部字段。然后,我们遍历所有声明的任务,并逐个将它们从源队列转移到目标队列。然后,我们将源队列的窃取头部更新为其真实头部;这表示窃取操作已经结束。最后,更新目标队列的尾部,以便消费者线程可以弹出被窃取的任务并执行它们。此过程如 图 6 所示。
为了简洁起见,示例中删除了所有与内存排序相关的代码。将任务推送到线程的运行队列时还有一些需要注意的细节:
- 如果队列不满,则任务将被简单地推回队列。
- 如果队列已满,并且当前有一个线程正在从队列中窃取任务(窃取头部和真实头部不相等),则表示运行队列很快就会变空,所以给定的任务将被推送到全局队列中。全局队列(也称为注入队列)是所有线程共享的链表,队列中任务的插入或删除由互斥锁保护。
- 如果队列已满,并且当前没有其他线程从本地运行队列窃取,则调用
push_overflow函数。此函数获取本地运行队列一半的任务,并批量添加到全局队列中。
工作线程(Workers)
列表 16 中概述了一些重要的数据结构。当创建多线程调度器时,也会创建一些工作线程(Workers)。每个工作线程都分配给一个新生成的线程(每个工作线程对应一个线程)。每个线程都会得到一个 Core 结构体的实例;此结构体包含本地运行队列、ticks 等数据。Shared 结构体包含跨所有工作线程(线程)共享的数据,例如全局队列(注入队列)、所有线程队列对应的 Steal 句柄列表(例如,remotes[2] 对应于第三个工作线程的运行队列的 Steal 句柄)以及其他一些结构。
/// Core data
struct Core {
tick: u32,
lifo_slot: Option<Task>,
/// The worker-local run queue.
run_queue: queue::Local,
is_searching: bool,
...
}
/// State shared across all workers
pub(super) struct Shared {
/// Per-worker remote state. All other workers have access
/// to this and is how they communicate between each other.
remotes: Box<[Remote]>,
/// Global task queue.
inject: Inject<Arc<Handle>>,
...
}
/// Used to communicate with a worker from other threads.
struct Remote {
/// Steals tasks from this worker.
steal: queue::Steal<Arc<Handle>>,
/// Unparks the associated worker thread
unpark: Unparker,
}core 结构体中的 LIFO 槽是消息传递场景的一种优化。当两个任务通过通道(channel)通信时,以下场景经常发生:
- Task1 和 Task2 通过通道通信。
- Task2 当前阻塞在通道的一侧,等待来自 Task1 的消息。
- Task1 通过通道发送消息。
- Task2 被唤醒并放置在运行队列的末尾。
这里的问题在于,由于 Task2 被放置在运行队列的末尾,因此 Task1 发送消息和 Task2 接收消息之间可能存在很大延迟。因此,Tokio 调度器有一个 LIFO(后进先出)槽,新任务被放置在其中,当调度器想要从队列中弹出任务时,它会首先检查 LIFO 槽是否有任务,只有在 LIFO 槽为空的情况下才会去查看队列头部的其他任务。
现在让我们看一下工作线程是如何创建的以及它们启动时会做什么。列表 17 展示了这个过程。首先,每个工作线程都在单独的新线程上运行。然后,工作线程会一直循环执行语句,直到运行时关闭。
Core 结构体的 tick 字段保存了工作线程在这个循环中的迭代次数。在第 15 行,tick 会增加。如果 tick 的值是 event_interval(共享调度器配置的一部分)的倍数,那么工作线程会在第 19 行尝试运行驱动程序。我们将在下一节讨论驱动程序。
在第 23 行,工作线程尝试获取一个任务。next_task 函数首先检查 LIFO 槽是否有任务,如果为空,则会从工作线程的本地运行队列中弹出一个任务。正如我们在上一章讨论过的,运行任务意味着拉取与其关联的 future。
第 30 行的 steal_work 函数会首先尝试从兄弟工作线程窃取任务到其运行队列中,并返回一个被窃取的任务(窃取机制之前已经解释过)。如果没有任务可以从兄弟那里窃取,它就会检查全局运行队列是否有任务。如果没有可用任务,工作线程就会停放(进入睡眠状态),直到任务激增促使其他线程唤醒这个工作线程。在进入睡眠状态之前,一些线程也可能会尝试获取并运行驱动程序。
... {
...
// as a part of the staring sequence
// of the runtime.
for worker in self.all_workers() {
runtime::spawn_thread(move || run(worker));
}
...
}
fn run(worker: Arc<Worker>) {
let core = worker.core.take();
while !core.is_shutdown {
// Increment the tick
core.tick();
if core.tick % self.worker.shared.handle
.config.event_interval == 0 {
// Run I/O Driver, Timer, ...
core = self.run_driver(core);
}
// First, check work available to the current worker.
if let Some(task) = core.next_task(&self.worker) {
core = self.run_task(task, core)?;
continue;
}
// There is no more **local** work to process, try to
// steal work from other workers.
if let Some(task) = core.steal_work(&self.worker) {
core = self.run_task(task, core)?;
} else {
// Wait for work
core = self.park(core);
}
}
...
}I/O 驱动程序
运行时驱动程序受互斥锁保护,同一时间只能有一个工作线程控制驱动程序。线程会定期尝试控制驱动程序(例如每 64 个 tick 一次)。运行时驱动程序由用于不同目的的不同驱动程序组成:I/O 驱动程序、时间驱动程序、进程驱动程序等。I/O 驱动程序负责监听来自操作系统的事件并调度与这些事件相关的资源。
在 列表 17 的第 20 行,当一个工作线程尝试运行运行时驱动程序时,它必须首先给互斥锁加锁,如果加锁成功(没有其他工作线程控制驱动程序),则工作线程可以继续。这里我们将重点关注运行时驱动程序的 I/O 驱动程序(当调用 run_driver 函数时,它会运行其内部驱动程序,包括 I/O 驱动程序)。
I/O 驱动程序包含一个数据结构,可以保存记录哪些资源与哪些事件相关。目前,Tokio 使用 Mio,它是 Rust 的一个底层 I/O 库;Mio 是对不同操作系统异步 API 的抽象 13。叶 future 通过 I/O 驱动程序提供的数据结构向 Mio 注册它们感兴趣的资源。然后,Mio 与操作系统交互,并使用底层操作系统提供的任何 API 传递这些事件。然后,I/O 驱动程序阻塞在来自 Mio 的 poll 函数调用上,并等待事件到达。从操作系统接收事件后,Mio 会将这些事件传递给 poll 的调用者,调用者的职责是处理应该通知哪些资源。
例如,在从套接字读取数据时,当任务阻塞等待套接字可读时,I/O 驱动程序的工作是获取来自 Mio 的事件,查看是否存在与套接字关联的事件,表明套接字现在可读,然后调用等待任务的 waker 的 wake() 方法。
列表 18 显示了运行 I/O 驱动程序时调用的函数。在第 5 行,准备一个事件数组(该数组在对 I/O 驱动程序的调用之间重用)。然后在第 9 行,运行驱动程序的线程会阻塞在对 poll 的调用上,将要填充的事件数组传递给它,并等待来自 Mio(因此也来自操作系统)的事件到达。一旦事件到达,它就会逐个迭代处理它们,并调度与它们相关的资源(例如将任务重新调度回运行队列)。
需要注意的一点是,任务都调度到控制驱动程序的 worker 的运行队列上,这就是之前我们说任务批量到达的原因。现在让工作窃取算法完成剩下的工作,并将任务分配给各个 worker。
fn turn(&mut self, max_wait: Option<Duration>) {
self.tick = self.tick.wrapping_add(1);
let mut events = self.events.take();
// Block waiting for an event to happen,
// peeling out how many events happened.
self.poll.poll(&mut events, max_wait);
// Process all the events that came in, dispatching appropriately
let mut ready_count = 0;
for event in events.iter() {
let token = event.token();
self.dispatch(token, Ready::from_mio(event));
ready_count += 1;
}
self.events = Some(events);
}小结
在本节中,我们介绍了 Tokio,Rust 的异步运行时。Tokio 在 异步编程 中扮演着执行器的角色。我们研究了多线程调度器的工作原理,以及工作窃取算法的原理及其重要性。然后,我们深入研究了调度程序使用的队列的实现以及工作窃取如何与它们配合工作。讨论了工作线程的内部工作原理,它们如何创建并运行在自己的线程上,它们使用的的数据类型及功能。最后,更深入地研究了从异步编程章节就开始讨论的 I/O 驱动程序。
io_uring
Linux 提供了一组用于执行异步 I/O 的系统调用。epoll 就是这样一个系统调用的示例,它被 Mio 用作其在 Linux 上的后端(参见 Tokio 章节的 I/O 驱动程序部分)。这些系统调用可以监视一组文件描述符,例如网络套接字,并检查它们的状态以进行 I/O 操作,例如查看套接字是否可读。
epoll 接受一个包含进程想要监视的文件描述符的兴趣集。然后它返回一个就绪列表(兴趣列表的子集),该列表是一组可以进行 I/O 的文件描述符;进程可以阻塞在 epoll_wait 系统调用上,直到内核返回一组就绪的文件描述符。
epoll 用于文件
能够将异步 I/O 用于文件系统操作对性能至关重要。大型 Web 服务器、SFTP 服务器、数据库和许多其他应用程序都需要 epoll 提供的异步性;因为当您拥有数千个请求和并发连接时,阻塞在文件系统上的读写操作会严重影响性能。
epoll 的问题在于它总是为文件返回就绪状态。事实上,epoll 只有应用于 I/O 操作时会阻塞的文件描述符时才有意义,例如网络套接字和管道。因此,Tokio 和其他编程语言的库会为文件操作使用线程池,这意味着当 future 想对文件执行 I/O 时,I/O 请求会发送到另一个线程并在那里同步执行。这就是 io_uring 的用武之地。 14
I/O Uring
io_uring 在 2019 年的 Linux Kernel 版本 5.1 中引入。io_uring 的目标是替换旧的异步 I/O 接口,并通过降低应用程序的开销来提高性能。io_uring 解决了常规文件的问题,并提供了一个统一的 API,供程序享受异步的好处。
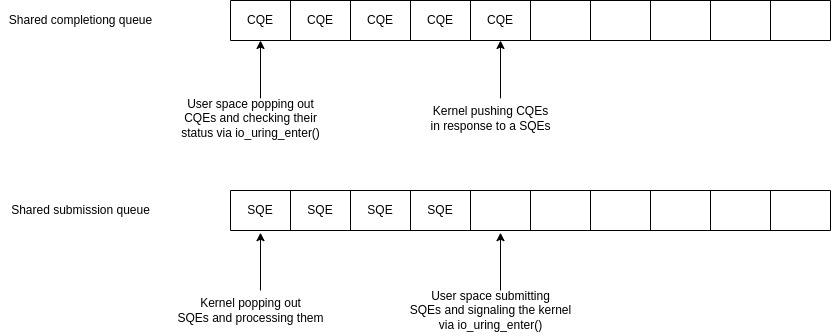
io_uring 使用两个环形缓冲区。一个用于向内核提交请求,另一个用于接收这些请求的完成情况。
程序使用 io_uring_setup() 系统调用来创建这两个环形缓冲区。这两个缓冲区使用 mmap 创建,目的是在用户空间和内核空间之间共享。这减少了在两者之间复制数据结构的开销。 15
提交以提交队列条目(submission queue entry, SQE)类型添加到提交缓冲区。SQE 是一个结构体,其字段可以支持程序所需的大量操作,例如从套接字读取、创建文件、写入文件等。将 SQE 添加到提交缓冲区后,程序可以调用 io_uring_enter() 系统调用来通知内核有可用的 SQE,并且内核应该开始读取它们。列表 19 中提供了简化版本的 SQE 结构体。
此结构体的不同字段根据操作的类型用于不同的目的。例如,如果您想做重命名操作,opcode 应使用 IOURING_OP_RENAMEAT(称为 io_uring_op 的巨大枚举中的一个情况),将 addr 设置为旧路径,将 addr2 设置为新路径;其他字段也可能需要填写。这实际上等同于 renameat2 系统调用。 16
struct io_uring_sqe {
__u8 opcode; /* type of operation for this sqe */
__u8 flags; /* IOSQE_ flags */
__s32 fd; /* file descriptor to do IO on */
union {
__u64 addr; /* pointer to buffer or iovecs */
...
};
union {
__u64 addr2;
...
};
__u32 len; /* buffer size or number of iovecs */
union {
__kernel_rwf_t rw_flags;
...
__u32 rename_flags;
...
};
__u64 user_data; /* data to be passed back
at completion time */
};处理完 SQE 后,内核会将完成队列条目(completion queue entries,CQE)提交到完成队列。完成队列中的每个 CQE 在提交队列条目中都对应一个 SQE。然后程序会读取这些 CQE 并根据其状态采取适当的操作。用户空间可以使用用于提交 SQE 的相同系统调用 io_uring_enter() 来阻塞并等待 CQE。
图 7 展示了这些缓冲区如何工作的简化视图。
这些工作可以批量提交和读取,因此系统调用的数量会显着减少,从而可以提高应用程序的性能。系统调用之所以会如此影响性能,部分原因是操作系统为避免 Spectre 和 Meltdown 等漏洞而采取的安全预防措施 17 18.
小结
我们讨论了 Linux内核为应用程序提供的异步 API,并深入研究了 epoll 的内部工作原理。然后我们讨论了 epoll 在进行异步文件操作时为何会遇到瓶颈,以及使用 epoll 的运行时为何必须使用线程池来进行文件 I/O。之后,io_uring 被引入作为解决 Linux 之前异步 I/O API 缺点的方案,并且我们研究了 io_uring 的工作原理。Tokio 一直在致力于 tokio_uring 项目,以试验 tokio 和 io_uring 的集成 19.
总结
这篇文章首先介绍了 Rust 编程语言;我们看到了所有权和借用等概念如何协同工作,并在编译时实现内存和类型安全。诸如 C/C++ 等传统语言因允许开发人员在管理内存时轻易犯错而臭名昭著,导致用这些语言编写的程序充斥着危险的安全漏洞。
然后我们将注意力转移到异步编程上,并讨论了不同的多任务方法,例如抢占式和协作式。我们概述了每种方法的优缺点,并总结出为了避免在请求数量急剧增加时内存饱和,我们可以使用异步任务(绿色线程)代替每个都拥有自己调用栈的传统线程。然后,我们简要介绍了 Rust 如何使编写异步程序与编写普通同步程序一样简单。讨论了 future 和编译器生成的 状态机,并介绍了我们需要 executors 来轮询这些 future,以及 wakers 使我们能够将 future 重新调度回运行时。
接下来,我们讨论了 Tokio(一个 Rust 的异步运行时)及其不同部分。我们深入研究了 tokio 如何调度任务,以及运行在线程上的工作者如何管理它们的运行队列。还讨论了 I/O 驱动程序及其注册资源的工作。在最后一章中,介绍了 Linux 操作系统的异步接口及其优缺点。我们讨论了 io_uring 如何被引入来解决之前异步接口的缺点。
参考文献
You can cite this work through this DOI. Alex Gaynor. What science can tell us about C and C++’s security. 2021. url: https://alexgaynor.net/2020/may/27/science-on-memory-unsafety-andsecurity/. ↩ Stack Overflow. Stack Overflow Developer Survey 2021. 2021. url: https://insights.stackoverflow.com/survey/2021#s:ection-most-loved-dreadedand-wanted-programming-scripting-and-markup-languages. ↩ The Rust Book. 2022. url: https://github.com/rust-lang/book. ↩ ↩2 ↩3 ↩4 Philipp Oppermann. Writing an OS in Rust: Async/Await Chapter. 2020. url: https://os.phil-opp.com/async-await/. ↩ ↩2 Rust RFC 2033 experimental coroutines. 2018. url: https://github.com/rust-lang/rfcs/blob/master/text/2033-experimental-coroutines.md. ↩ Rust RFC 2592 Future API. 2018. url: https://github.com/rust-lang/rfcs/blob/master/text/2592-futures.md. ↩ ↩2 ↩3 Rust RFC 2394 async/await. 2018. url: https://github.com/rust-lang/rfcs/blob/master/text/2394-async_await.md. ↩ ↩2 ↩3 The Rust Unstable Book. 2022. url: https://doc.rust-lang.org/beta/unstable-book/language-features/generators.html. ↩ Crate futures 0.1.30, Trait futures::future::Future. 2018. url: https://docs.rs/futures/0.1.30/futures/future/trait.Future.html. ↩ Rust Documentation, Trait std::future::Future. 2022. url: https://doc.rust-lang.org/std/future/trait.Future.html. ↩ Tokio: A runtime for writing reliable asynchronous applications with Rust. Provides I/O, networking, scheduling, timers, … 2022. url: https://github.com/tokio-rs/tokio. ↩ Carl Lerche. Making the Tokio scheduler 10x faster. 2019. url: https://tokio.rs/blog/2019-10-scheduler. ↩ Mio: Metal IO library for Rust. 2022. url: https://github.com/tokio-rs/mio. ↩ Lord of the io uring: Asynchronous Programming Under Linux. 2022. url: https://unixism.net/loti/async_intro.html. ↩ liburing manual: io uring.7. 2022. url: https://git.kernel.dk/cgit/liburing/tree/man/io_uring.7. ↩ liburing manual: io uring enter.2. 2022. url: https://git.kernel.dk/cgit/liburing/tree/man/io_uring_enter.2. ↩ Paul Kocher et al. “Spectre Attacks: Exploiting Speculative Execution”. In: 40th IEEE Symposium on Security and Privacy (S&P’19). 2019. ↩ Moritz Lipp et al. “Meltdown: Reading Kernel Memory from User Space”. In: 27th USENIX Security Symposium (USENIX Security 18). 2018. ↩ A crate that provides io-uring for Tokio by exposing a new Runtime that is compatible with Tokio but also can drive io-uring-backed resources. 2022. url: https://github.com/tokio-rs/tokio-uring. ↩