【译】每个请求,每一微秒:Cloudflare 的可扩展机器学习
原文:Every request, every microsecond: scalable machine learning at Cloudflare
链接:https://blog.cloudflare.com/scalable-machine-learning-at-cloudflare/
日期:2023 年 6 月 19 日
这篇文章将向您介绍我们在机器学习方面取得的进步。我们的技术方案能够承载机器学习特征和模型数量的爆炸性增长,同时极大减少每个 HTTP 请求的处理时间。下面让我来为您揭秘。
背景
要全面理解我们不断演化的方法,最好先了解机器学习检测(machine learning detections)是如何工作的。Cloudflare 平均每秒处理超过 4600 万个 HTTP 请求,在高峰时段每秒超过 6300 万。
机器学习检测在确保这个庞大网络的安全性和完整性方面发挥着至关重要的作用。实际上,它是我们所有检测机制中请求量最大的那个,为超过 72% 的 HTTP 请求提供最终的 机器人评分决策。除此之外,我们针对每个 HTTP 请求在影子模式下运行多个机器学习模型。
给力的伙伴 CatBoost,是我们机器学习基础设施的核心。它支持超低延迟模型推理,并且对新型威胁也有高质量的预测结果,如 阻止针对移动应用程序的机器人。然而,机器学习模型推理终究只是整个延迟公式的一个组成部分。其他关键部分包括机器学习特征提取和准备。在追求最佳性能的过程中,我们不断优化导致系统整体延迟的各个方面。
最初,我们的机器学习模型依赖于单一请求特征(single-request features),例如某些请求头的存在与否或它的值。然而,由于这些属性很容易伪造,我们改进了方法。我们转而使用请求间特征(inter-request features),该特征利用滑动时间窗口中请求的多个维度的聚合信息。例如,我们现在考量与某些请求属性相关的唯一 user agents 的数量等因素。
请求间特征的提取和准备由我们基于 Go 开发的特征服务平台 Gagarin 处理。当请求到达 Cloudflare 时,我们从请求属性中提取维度键(dimension keys)。然后在 多级缓存 中查找对应的机器学习特征。如果在缓存中找不到所需的机器学习特征,则会向 Gagarin 发出一个会被内存缓存的(memcached) “GET” 请求以获取这些特征。然后,机器学习特征被送入到 CatBoost 模型中以生成检测结果,然后通过 Firewall 和 Workers 以及通过我们内部的 导入 ClickHouse 的日志记录管道 呈现给客户。这使得我们的数据科学家能够进行进一步的实验,产生更多的特征和模型。
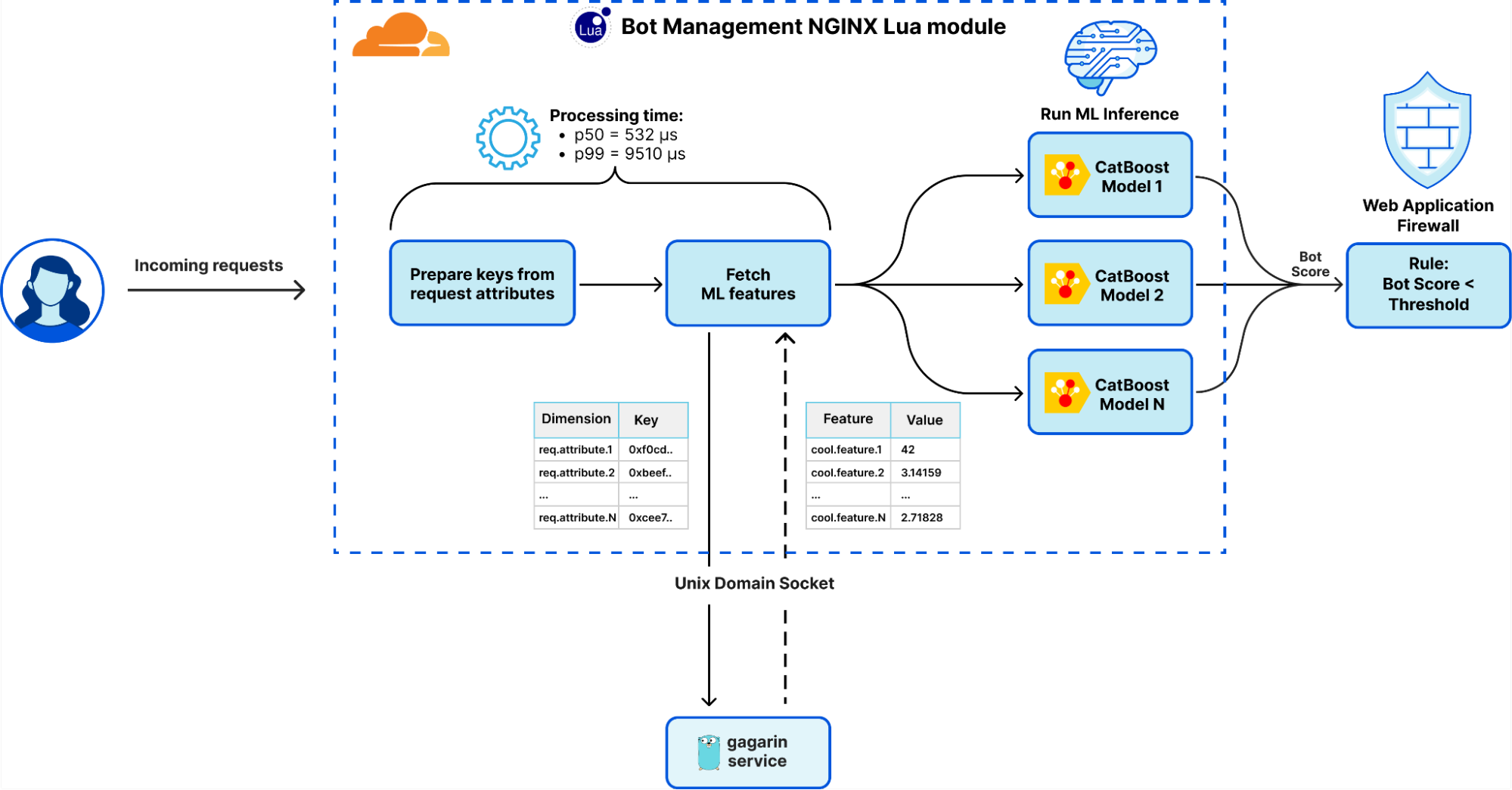
最初,Gagarin 在延迟上表现不错,托管所有机器学习特征的延迟中位数约为 200 微秒。然而,随着系统的发展,我们引入了更多的特征和维度键,再加上流量的增加,缓存命中率开始下降。延迟中位数已增加至 500 微秒,在高峰时段,延迟显着恶化,p99 延迟飙升至大约10 毫秒。Gagarin 经历了大规模的底层调整、优化、分析和基准测试。尽管做出了这些努力,我们还是遇到了使用 Unix Domain Socket (UDS) 的进程间通信 (IPC) 的限制,以及下面探讨的其他挑战。
问题定义
综上所述,之前的解决方案有其缺点,包括:
- 高尾部延迟:在高峰时段,部分请求由于 Unix socket 和 Lua 垃圾收集器上的 CPU 争用而导致延迟增加。
- 资源利用率没有达到最优:没有充分使用 CPU 和 RAM,为服务器上运行的其他服务留下的资源较少。
- 机器学习特征可用性:由于 memcached 超时而降低,这导致部分请求更可能误报或漏报。
- 扩展性限制:随着我们添加更多的机器学习特征,我们达到了基础设施的扩展性上限。
在对挑战有了全面的了解并有了可量化的指标后,我们进入了下一阶段:寻求一种更有效的方法来获取和托管机器学习特征。
探索解决方案
在寻求更有效的获取和托管机器学习特征的方法过程中,我们评估了几种替代方案。主要方法包括:
进一步优化 Gagarin:当我们将基于 Go 的 memcached 服务器优化到极限时,延迟的减少也到达了极限。这是由于 UDS 上的 IPC 同步开销、多次数据拷贝、序列化/反序列化开销以及 Go 中垃圾收集器的固有延迟和哈希查找的性能引起的。
考虑 Quicksilver:我们考虑使用 Quicksilver,但机器学习特征的数量和更新频率引起了容量问题以及对其他用例的潜在负面影响。此外,它使用带有 memcached 协议的 Unix 套接字,同样遇到前述限制。
增加多级缓存大小:我们研究了扩展缓存大小以容纳数千万个维度键。然而,由于键重复及其跨工作线程的机器学习特征的重复,导致相关的内存消耗,使得这种方法不可行。
对 Unix 套接字进行分片:我们考虑对 Unix 套接字进行分片以减轻争用并提高性能。尽管显示出潜力,但这种方法仅部分解决了问题并引入了更多的系统复杂性。
切换到 RPC:我们探索了使用 RPC 在前线服务器和 Gagarin 之间进行通信的选项。然而,由于 RPC 仍然需要某种形式的通信通道(例如 TCP、UDP 或 UDS),因此与 UDS 上的 memcached 协议相比,它不会显着改变性能,而 UDS 已经很简单且简约。
在考虑了这些方法之后,我们将重点转向研究替代的进程间通信 (IPC) 机制。
进程间通信机制
从 第一性原理 出发,我们提出的问题是,“操作系统提供的进程间数据传输最有效的底层方法是什么?”我们的目标是找到一种解决方案,能够直接从内存中为相应的 HTTP 请求提供机器学习特征。通过消除对 Unix 套接字的依赖,我们可以减少 CPU 争用、改善延迟并最大限度地减少数据拷贝。
为了确定最有效的 IPC 机制,我们评估了 Linux 生态系统中各种可用选项。我们使用 ipc-bench,一个专门为此目的而设计的开源基准测试工具,来测量我们的测试环境中不同 IPC 方法的延迟。测量方法是,在两个进程之间来回发送一百万个 1,024 字节的消息(即 ping pong)。
| IPC method | 平均持续时间,μs | 平均吞吐量,消息/秒 |
|---|---|---|
| eventfd(bi-directional) | 9.456 | 105,533 |
| TCP sockets | 8.74 | 114,143 |
| Unix domain sockets | 5.609 | 177,573 |
| FIFO(named pipes) | 5.432 | 183,388 |
| Pipe | 4.733 | 210,369 |
| Message Queue | 4.396 | 226,421 |
| Unix Signals | 2.45 | 404,844 |
| Shared Memory | 0.598 | 1,616,014 |
| Memory-Mapped Files | 0.503 | 1,908,613 |
根据我们的评估,我们发现 Unix 套接字虽然负责同步,但并不是最快的 IPC 方法。两种最快的 IPC 机制是共享内存和内存映射文件。两种方法都提供相似的性能,前者使用 /dev/shm 中的特定 tmpfs 卷和专用系统调用,而后者可以存储在任何卷中,包括 tmpfs 或 HDD/SDD。
缺失的一环
鉴于这些发现,我们决定采用 内存映射文件 作为 IPC 机制来托管机器学习特征。这一选择有望减少延迟、减少 CPU 争用以及最少的数据拷贝。然而,它本身并不提供像 Unix 套接字那样的数据同步功能。与 Unix 套接字不同,内存映射文件只是 Linux 卷中可以映射到进程内存的文件。这引发了几个关键问题:
- 在处理文件时,我们如何有效地获取给定维度键的数百个浮点数特征数组?
- 如何保证对千万级键进行安全的、并发的频繁更新?
- 我们如何避免前述方法在 Unix 套接字中遇到的 CPU 争用?
- 如何有效支持未来更多维度和特征的增加?
为了应对这些挑战,我们需要补上这缺失的一环。
放大创意
使用内存映射文件来托管机器学习特征,为了实现这一创想,我们需要采用几个关键策略,涉及数据同步、数据结构和反序列化等方面。
Wait-free synchronization 无等待同步
在处理并发数据时,确保安全的、并发的和频繁的更新至关重要。传统的锁往往不是最有效的解决方案,尤其是在处理高并发环境时。以下是三种不同同步技术的概述:
有锁同步(With-lock synchronization):一种使用互斥锁或自旋锁等机制的常见方法。它确保在给定时间只有一个线程可以访问资源,但可能会遇到争用、阻塞和优先级反转,就像 Unix 套接字一样明显。
无锁同步(Lock-free synchronization):这种非阻塞方法采用原子操作来确保至少有一个线程始终前进。它消除了传统的锁,但需要小心处理边缘情况和竞争条件。
无等待同步(Wait-free synchronization):一种更先进的技术,可保证每个线程都取得进展并完成其操作,并且不会被其他线程阻塞。与无锁同步相比,它提供了更强的进度保证,确保每个线程在有限步骤内完成操作。
| Disjoint Access Parallelism | Starvation Freedom | Finite Execution Time | |
|---|---|---|---|
| With lock | ❌ | ❌ | ❌ |
| Lock-free | ✅ | ❌ | ❌ |
| Wait-free | ✅ | ✅ | ✅ |
我们的 无等待 数据访问模式的灵感来自 Linux内核的读取-拷贝-更新(RCU)模式 和 左右并发控制技术。在我们的解决方案中,我们在独立的内存映射文件中维护数据的两个副本。对此数据的写访问由单个写入器管理,多个读取器能够同时访问该数据。
我们将同步状态,就是用于协调对这些数据副本的访问,存储在第三个内存映射文件中,称为“状态”(state)。该文件包含一个 64 位的原子整数,它代表一个实例版本(InstanceVersion) 和一对额外的 32 位原子变量,用于跟踪每个数据副本的活跃读取器数量。实例版本由当前活跃的数据文件索引(1 位)、数据大小(39 位,可容纳高达 549 GB 的数据大小)和数据校验和(24 位)组成。
零拷贝反序列化
为了有效地存储和获取机器学习特征,我们需要解决反序列化延迟的挑战。恰好,零拷贝反序列化 提供了答案。该技术通过直接引用序列化形式的字节来减少访问和使用数据所需的时间和内存。
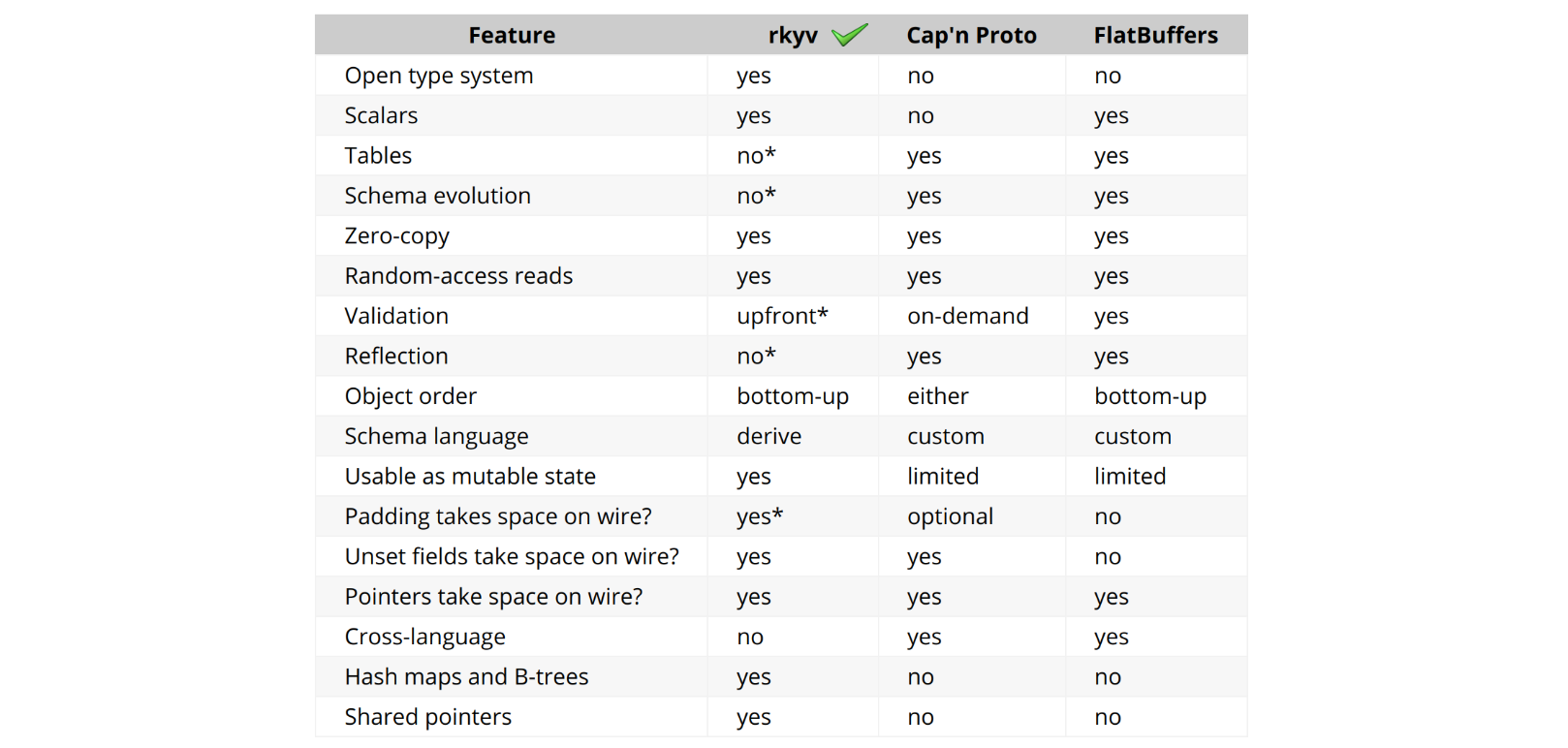
我们借助 rkyv(Rust 中的一个零拷贝反序列化框架)来帮助我们完成这项任务。rkyv 实现了完全零拷贝反序列化,这意味着在反序列化过程中不会复制任何数据,并且不会执行反序列化数据的工作。它通过结构化其编码表示匹配源类型的内存表示来实现这一点。
我们的解决方案所依赖的 rkyv 的关键功能之一是,它能够以零拷贝方式访问哈希表(HashMap)。这是 Rust 序列化库中的独有功能,也是我们在实现中选择 rkyv 的主要原因之一。它还拥有一个充满活力的 Discord 社区,热情地提供最佳实践并满足功能请求。
mmap-sync crate
利用内存映射文件、无等待同步和零拷贝反序列化的优势,我们精心设计了一个独特而强大的工具,用于管理进程间的高性能、并发数据访问。我们已将这些概念打包到一个名为 mmap-sync 的 Rust Crate 中。为了繁荣整个社区,我们乐意将其开源。
mmap-sync 库的核心是一个名为 Synchronizer 的结构。它提供了一种读取和写入任何可表示为 Rust Struct 数据的途径。用户只需在 struct 定义旁实现或派生一个特定的 Rust Trait——该任务仅需要一行代码。Synchronizer 提供了一个简单优雅的接口,需要实现“write”和“read”方法。
impl Synchronizer {
/// Write a given `entity` into the next available memory mapped file.
pub fn write<T>(&mut self, entity: &T, grace_duration: Duration) -> Result<(usize, bool), SynchronizerError> {
…
}
/// Reads and returns `entity` struct from mapped memory wrapped in `ReadResult`
pub fn read<T>(&mut self) -> Result<ReadResult<T>, SynchronizerError> {
…
}
}
/// FeaturesMetadata stores features along with their metadata
#[derive(Archive, Deserialize, Serialize, Debug, PartialEq)]
#[archive_attr(derive(CheckBytes))]
pub struct FeaturesMetadata {
/// Features version
pub version: u32,
/// Features creation Unix timestamp
pub created_at: u32,
/// Features represented by vector of hash maps
pub features: Vec<HashMap<u64, Vec<f32>>>,
}通过 Synchronizer 执行的读操作是零拷贝反序列化的,并返回一个“受保护的(guarded)”的 Result,其使用 RAII 设计模式 封装了对 Rust struct 的引用。此操作还会增加使用该 struct 的活跃读取器的原子计数器。一旦 Result 离开作用域,Synchronizer 就会在计数器中减去这些读取器的数目。
mmap-sync 中使用的同步机制不仅是“无锁的”而且是“无等待的”。这确保了操作完成之前将采取的步骤数的上限,从而提供了性能保证。
数据存储在共享映射内存中,允许 Synchronizer 同时“写入”和“读取”数据。这种设计使得 mmap-sync 成为一个管理共享和并发数据访问的高效且灵活的工具。
现在,了解了 mmap-sync 的底层机制后,让我们探索这个库如何在我们的机器人管理平台的更广泛环境中发挥关键作用,特别是在新开发的组件:bliss 服务和库中。
系统设计大翻修
从基于 Lua 模块,通过 Unix 套接字发出 memcached 请求,转变为 Go 中的 Gagarin 来获取机器学习特征,我们的新设计代表了重大演变。这一变化聚焦于我们新开发的 Rust 库 mmap-sync 的引入,为性能大幅升级奠定了基础。这一变化导致了系统全部重新设计,并引入了两个新组件,它们构成了我们的 Bots Liquidation Intelligent Security System (机器人流动智能安全系统)(或BLISS)的支柱,简而言之:bliss 服务和 bliss 库。
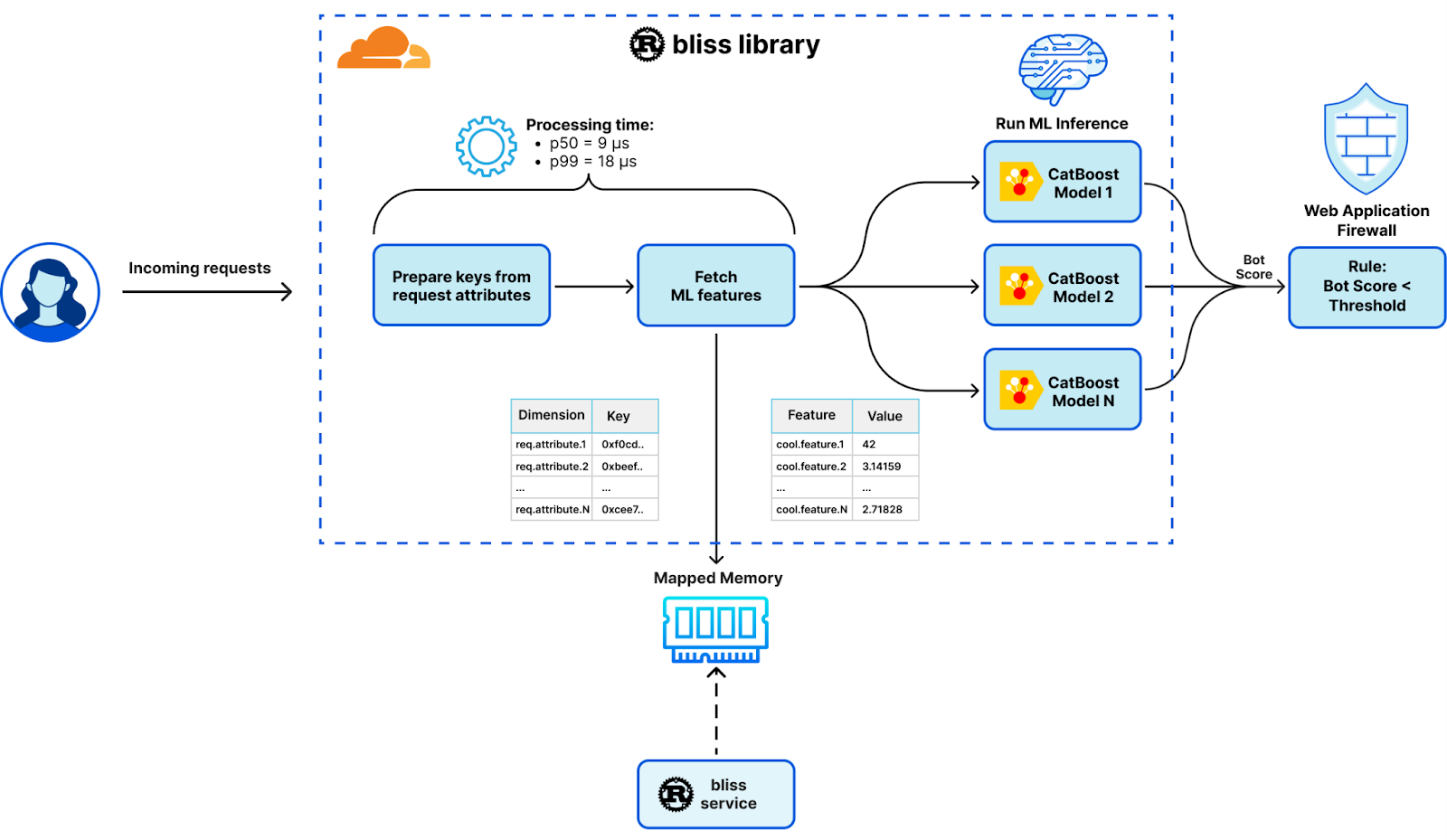
Bliss 服务
bliss 服务作为基于 Rust 的多线程 sidecar 守护进程运行。它专为优化大量数据和大量 I/O 操作的批处理而设计。它的关键功能包括获取、解析和存储机器学习特征和维度,以便轻松访问和操作数据。这是通过嵌入 Tokio 事件驱动平台实现的,该平台允许高效、非阻塞的 I/O 操作。
Bliss 库
作为单线程动态库运行,bliss 库通过 Lua 模块使用外部函数接口 (FFI) 无缝集成到每个工作线程中。这个轻量级库针对资源使用最小化和超低延迟进行了优化,无需大量 I/O 操作即可执行任务。它高效地托管机器学习特征并生成相应的检测结果。
除了利用 mmap-sync 库进行高效地获取机器学习特征,我们的新设计还包括其他几个性能改进:
- 无堆内存分配操作(Allocations-free operation): bliss 库重复使用预分配的数据结构,并且不执行堆内存分配,仅执行低成本栈内存分配。为了确保我们的零分配政策,我们使用 dhat 堆分析器 运行集成测试。
- SIMD 优化(SIMD optimizations):bliss 库尽可能使用矢量化 CPU 指令。例如,AVX2 和 SSE4 指令集用于加快某些请求属性的十六进制解码,将速度提高了十倍。
- 编译器调优(Compiler tuning):我们使用以下 flags 编译 bliss 服务和库,以获得卓越的性能:
[profile.release]
codegen-units = 1
debug = true
lto = "fat"
opt-level = 3- 基准测试和分析(Benchmarking & profiling):我们使用 Criterion 对 bliss 中的每个主要功能或组件进行基准测试。此外,我们还可以在 Criterion 基准测试上使用 Go pprof 分析器来查看火焰图等:
cargo bench -p integration -- --verbose --profile-time 100
go tool pprof -http=: ./target/criterion/process_benchmark/process/profile/profile.pb对我们系统的全面检修不仅简化了我们的运营,而且还有助于提高我们的机器人管理平台的整体性能。接下来就是见证奇迹的时刻。
发布结果
系统的重新设计带来了一些真正“幸福”(blissful)的红利。最重要的是,我们对无缝用户体验的承诺和客户的信任引导着我们的创新。我们确保无缝过渡到新设计,保持完全向后兼容,没有误报或漏报的客户报告。这证明了新系统的稳健性。
正如一句古老的格言所说,是骡子是马拉出来遛遛。当检验重新设计所带来的显着延迟改进时,这一点再真实不过了。与之前的系统相比,Cloudflare 的 HTTP 请求整体处理延迟平均降低了 12.5%。
这一改进在机器人管理模块中更为显着,延迟平均改善了 55.93%。
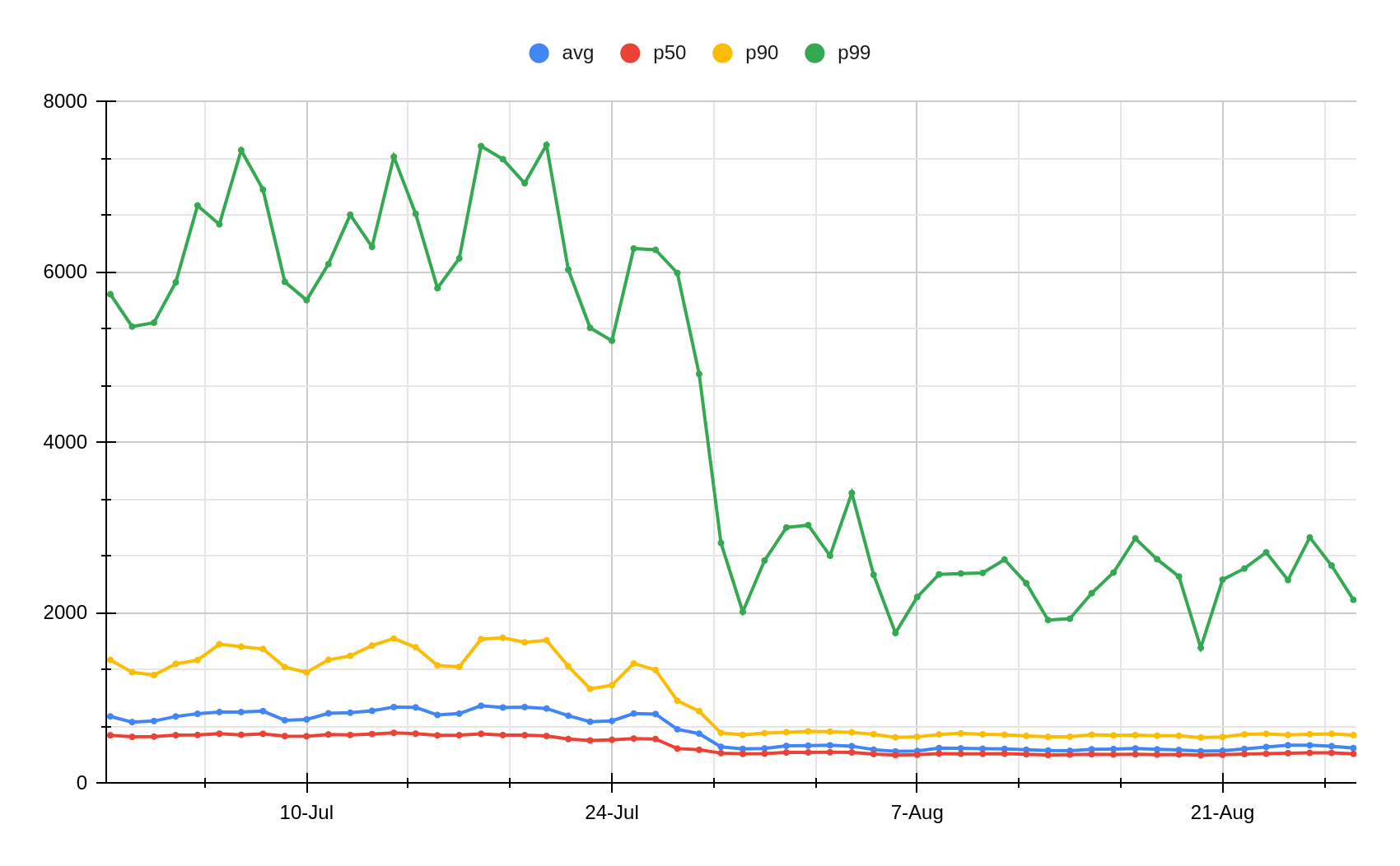
具体来说,我们的机器学习特征获取延迟已改善了几个数量级:
| 延迟指标 | 之前(μs) | 之后(μs) | 改变 |
|---|---|---|---|
| p50 | 532 | 9 | -98.30% 或 x59 |
| p99 | 9510 | 18 | -99.81%或x528 |
| p999 | 16000 | 29 | -99.82%或x551 |
要真正理解这种影响,请考虑以下因素:Cloudflare 的平均每秒 4600 万个请求,每个请求节省 523 微秒相当于每天节省超过 24,000 天或 65 年的处理时间!
除了延迟改进之外,我们还从此次发布中获得了其他好处:
- 增强特征可用性:由于消除了 Unix 套接字超时,机器学习功能的可用性现在达到了 100%,从而减少了检测中的误报和漏报。
- 提高资源利用率:系统的彻底重造释放了相当于数千个 CPU 核心和数百 GB RAM 的资源——显着提高了我们服务器集群的效率。
- 代码清理:另一个积极的副产品是我们的 Lua 和 Go 代码。数千行性能较差、内存安全性较差的代码已被淘汰,从而减少了技术债务。
- 升级机器学习能力:最后但同样重要的是,我们显著扩展了机器学习特征、维度和模型。此次升级使我们的机器学习推理能够处理数百个机器学习特征以及数十个维度和模型。
结论
经过重新设计,我们构建了一个强大而高效的系统,真正体现了“幸福”的本质。利用内存映射文件、无等待同步、无分配操作和零拷贝反序列化的优势,我们建立了稳健的基础架构,能够保持峰值性能,同时显着降低延迟。在我们走向未来的过程中,我们致力于利用这个平台来进一步改进我们的安全机器学习产品并孕育创新功能。此外,我们很高兴通过开源 Rust 库 mmap-sync 分享该技术的部分内容。
当我们迈向未来时,我们正在利用平台令人印象深刻的功能,探索新的途径来增强机器学习的力量。我们正在与精选客户一起部署基于 BLISS 的新机器学习模型。如果您是机器人管理用户并想要测试新模型,请联系您的客户团队。
另外,我们正在寻找更多希望在边缘网络运行自己机器学习模型的 Cloudflare 客户。如果您是一名开发人员,考虑在您的应用程序中切换到 Workers,请注册我们的 Constellation AI 封闭测试版。如果您是机器人管理客户,并且希望在边缘运行已经经过训练的轻量级模型,我们 很乐意听取您的意见。让我们一起走上这条幸福之路吧。